CDC(Change Data Capture)是一种通过监测数据变更(变更包括新增、修改、删除等)而对变更的数据进行进一步处理的一种设计模式,通常应用在数据仓库以及和数据库密切相关的一些应用上,比如数据同步、备份、审计、ETL等。实际上,早在二十多年前,CDC就已经用来将应用系统的数据变更实时发送到数据仓库,进一步转换后传递到数据分析系统^[Streaming Change Data Capture by Itamar Ankorion, Dan Potter, Kevin Petrie],这样能够在极小地影响生产的情况下,有效而及时地将数据传递到消费方。而在微服务架构逐渐流行的今天,这种古老的技术是否能够焕发新的生机?

CDC实现原理
在说CDC在微服务中的应用之前,我们有必要先了解一下CDC的基本原理。关键也许就在如何监测数据的变更。拿MySQL来说,我们知道MySQL中有binlog(binary log)可以记录用户对数据库进行的修改事件^[[mysqlbinlog — Utility for Processing Binary Log Files ](https://dev.mysql.com/doc/refman/5.6/en/mysqlbinlog.html)],顺理成章,一个最简单高效的CDC实现就可以利用binlog来完成。当然现在已经有很多开源的MySQL CDC实现,开箱即用。使用binlog并不是唯一的途径,至少对于MySQL而言,甚至利用数据库触发器也能完成类似的功能,但从效率上以及对数据库影响的层面来看可能就相形见绌了。
通常而言,CDC捕获到数据库的变更之后,会将变更事件发布到消息队列中供消费者消费,例如Debezium,将MySQL(也支持PostgreSQL、Mongo等)的变更持久化到Kafka中,我们通过订阅Kafaka中的事件,来实现我们需要的功能。
微服务解耦
我们刚才已经了解到,通过CDC,我们可以把数据库的变更转变为各个“事件”,从而可以只关心这些事件来处理。对于传统的大型单体应用,我们可以通过这种方式来进行解耦,从而拆分出微服务出来。同样,如果已经是微服务架构,有时候也可以运用CDC来简化服务间的调用。
举个例子,我们在奔驰OTR中有这样的场景:
- 系统中会创建客户服务的预约,预约将分配给一个用户去处理
- 这些预约可能是用户手动创建的,也可能是通过第三方系统发送过来的
- 当系统中创建了预约、或者预约修改后,相关的用户会收到通知信息
很容易我们可以拆分出预约、通知两个服务出来,为了实现通知的功能,如果采用直接的做法,我们在通知的服务中定义了一个接口是给某用户发送通知,这样我们在所有预约创建、修改的地方都需要进行相应的逻辑判断,并调用这个接口来发送通知。而实际上,我们有好几处地方都在创建或者修改预约信息,当这些业务代码需要修改的时候,我们都需要关心通知的部分是否需要作出修改。虽然我们很小心的在维护这部分代码,但还是很容易会漏掉一些地方的通知逻辑,或者出现业务上不一致的情况。
试想如果我们利用CDC的方式,不是直接显示的在预约变更的地方调用通知接口,而是监控预约表的变化,然后有一个地方统一的进行处理并发送通知,这样可以极大的降低业务代码的复杂度。同时要考虑的是,这样不再是一个同步的操作,这个延时对于业务场景是否能接受。在我们这个案例中,消息发送(通过第三方平台)本身就已经是一个异步调用了,业务上并没有发生变化,是可以考虑的。
Data replication
Martin Fowler在他关于Event-Driven Architecture的演讲中提到一个使用事件传递业务变更来解决跨服务的信息共享问题^[GOTO 2017 • The Many Meanings of Event-Driven Architecture • Martin Fowler]。

上图的架构中在Insurance Quoting服务中保存了一份customer的信息,这样当有需要查询的时候,不需要去调用customer management服务,而是直接从自己的副本中进行查询,这样做有一些好处:
- 提高了查询性能,直接从数据库里面拿,省去了远程调用
- 不用担心另外一个服务挂掉或者性能造成的影响,customer management挂了还可以用
- 缓解了customer management的压力
虽然好处不少,但是实现起来也不是那么容易,最大的问题就在于如何保证数据的一致(同步):数据发生了变化,如何告诉给我们?使用CDC来完成这个操作是比较合适了。通过CDC,我们可以将依赖系统的数据(只需要处理我们关心的部分)replicate到自身系统中,来支持自身系统的业务需要。
本质上,这样和MySQL的主从复制类似;好处在于,对于异构的系统,能够有较为统一的方式完成数据的同步。比如customer management存储在mysql,而我们可能使用mongodb或者postgresql,只要customer management能支持CDC,是可以很方便的将customer management的数据迁移过来。
实现CQRS
刚才提到的一个场景是消息通知,和类似的还有用户积分变更、数据统计及报表、用户行为分析等,通常这类业务对实时性要求不高,但又经常伴随着实时性要求较高的业务而发生,可以认为是一些用户行为导致的副作用。在上面的例子中,我们通过维护一个只读的customer数据库来进行查询操作,从某种意义上来讲算是读写分离了。CQRS^[Command Query Responsibility Segregation]正是一种读写分离的策略,对于查询和写操作分别用不同的模型,来优化查询的表现。
Example of CQRS^CQRS Pattern(/images/CQRS_demo.png)
如图所示,我们分别用两个不同的数据库来支持查询和写入的部分,将其分割开来。这样对于查询来说,是可以进行优化的,比如可以选择NoSQL来结构化视图,查询的时候不需要进行太多额外的处理,并可以考虑根据读操作和写操作不同的性能要求进行伸缩。
在这样应用CQRS的架构中,CDC就可以用来将写入的事件同步到查询的数据库中,在上图中左侧的Events位置,我们不需要在业务代码中去显示地发布事件,只需要通过CDC来监测写库中的改变即可。
CDC与Event Sourcing
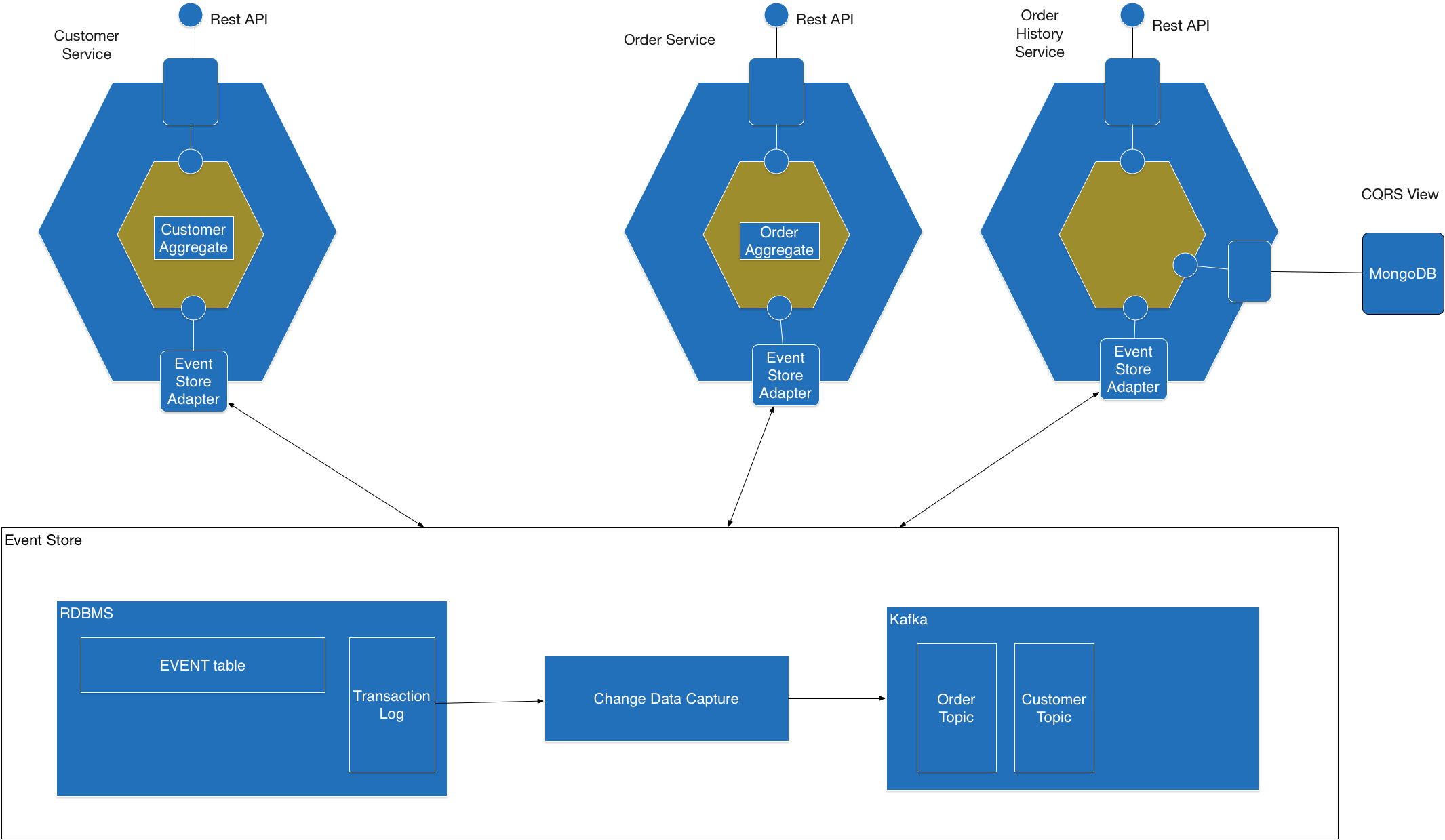
其实说到CRQS,通常都会和Event Sourcing结对出现。Event Sourcing可能是事件驱动架构的终极实现了,在这种架构的系统中,只存储客观事实也就是事件,而业务数据的状态,是通过"播放"事件而得到的。Event Sourcing是一种较为复杂的架构,通常DDD + EventSourcing搭配起来效果更好,但要完整的实现这样一个架构不是一件容易的事情。好在有一些开源的实现,可以供我们学习和参考。
Eventuate Local Architecture^Eventuate Local(https://raw.githubusercontent.com/eventuate-local/eventuate-local/master/i/Eventuate%20Local%20Big%20Picture.png)
{kind=link}
上图是Eventuate Local的架构,这是一个CQRS+EventSourcing的开源实现。对于EventSourcing来说比较重要的是需要一个Event Store,它有几个比较重要的功能:
- 将事件可靠的持久化(只能新增新的事件而不能改变已经存在的事实)
- 根据一个ID查出一个实体上的所有有序的事件
- 将事件广播出去(当然这不应该是Event Store的职责,我们姑且认为是一体的,不然后面不好写了)
利用RDBMS来保存事件是比较简单的一个操作了,需要注意的是需要保证事件的强一致性,在并发情况下,同一个聚合下多个事件同时发生的时候,需要保证这些事件依然是有序的,这里可以采取乐观锁的方式实现。
Eventuate中有一个CDC Service的服务,实现了Event Store同时支持了事件的发布。通过对Event表进行监测,新产生的事件被发布到Kafka中,供其他service消费,这样一个过程比较自动,不用过多担心持久化和手动进行事件发布中间有一个环节出错的情况了。
Puncturing encapsulation with change data capture
从上面的例子中可以看到CDC是一个比较有用的设计模式,在微服务架构中大有用武之地。那为啥技术雷达要把这个列到HOLD中^[technology radar]?
关键不在于CDC,而是打开方式不对。技术雷达中有提到:
>We're seeing some projects use CDC for publishing row-level change events and directly consuming these events in other services.
意思是说有一些项目在实现CDC的时候,直接将底层的事件暴露出来,这个”底层“意思是指没有经过处理的、原始的、和上游系统强绑定的。举个例子,在上面的Event Store的实现中,我们很容易就能实现一个存储Event的表^[Building an Event Storage]:
Column Type
-----------
AggregateId UUID Type Varchar Content Varchar Version Integer
而我们是在存储Event的内容的时候,可以选择以Json的方式存储,也可能会直接序列化成二进制格式,如果我们不加修改就直接将这个表的变化广播出去,那么下游系统就会依赖于我们的存储结构了,而且需要自己进行数据加工才能得到自己想要的数据。换而言之,如果我们以后发生改变,那所有的订阅者都得跟着改,这个是一个很大的隐患,会使得服务间的集成相当脆弱。
那么,更好的做法是什么呢?我觉得DDD可能是解决事件驱动架构问题的一个好的途径,通过DDD的方式,我们需要思考清楚真正业务场景中的聚合与事件,建立正确的模型,从而隔离原始的数据存储,当服务底层发生变化时,只需要修改这一层的实现即可无缝迁移。
以上都是纸上谈兵,到目前为止还没有在项目中实际运用过,不清楚我司的项目是不是有使用CDC的例子?比较好奇的是技术雷达的作者们是咋知道有些项目"use CDC for publishing row-level change events"?